LLM Fine-tuning Course
LiveFine-tuning a 3B language model end-to-end on the HF Hub: SFT, DPO, and a vision-language sidetrack
SmolLM3-3B
Base Model
SFT + DPO
Methods
4
Adapters Shipped
~$12
Total Compute
Overview
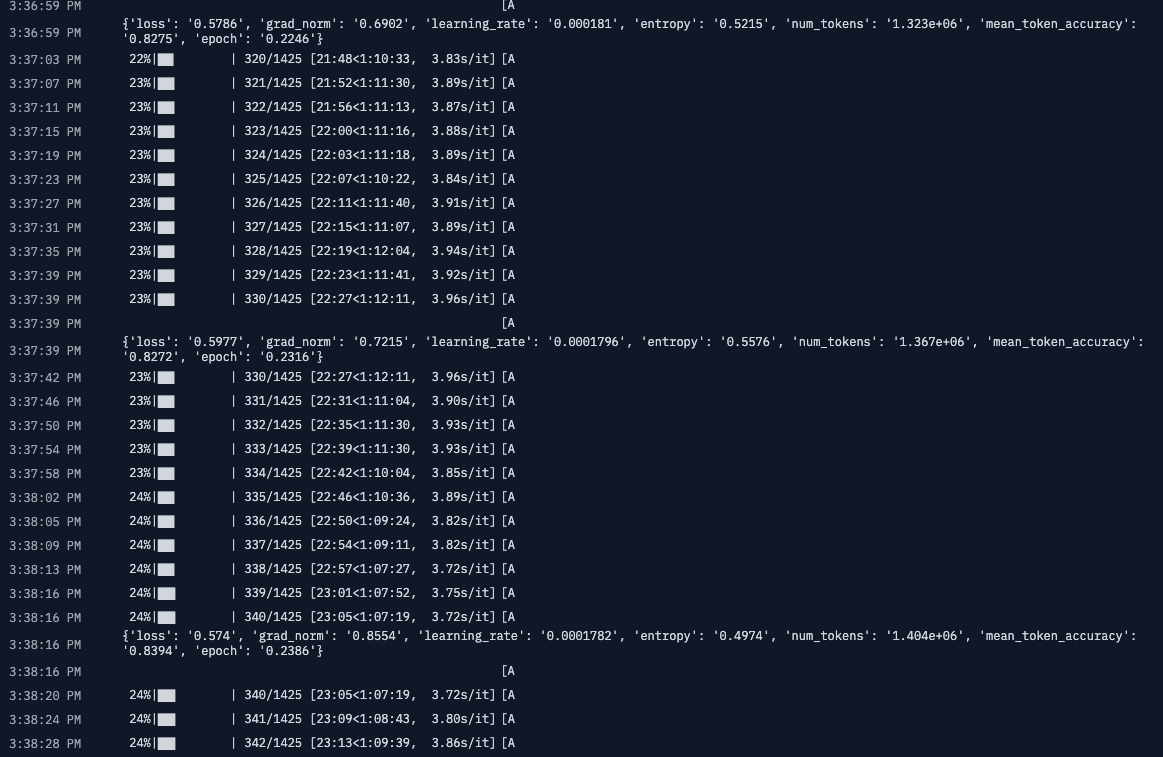
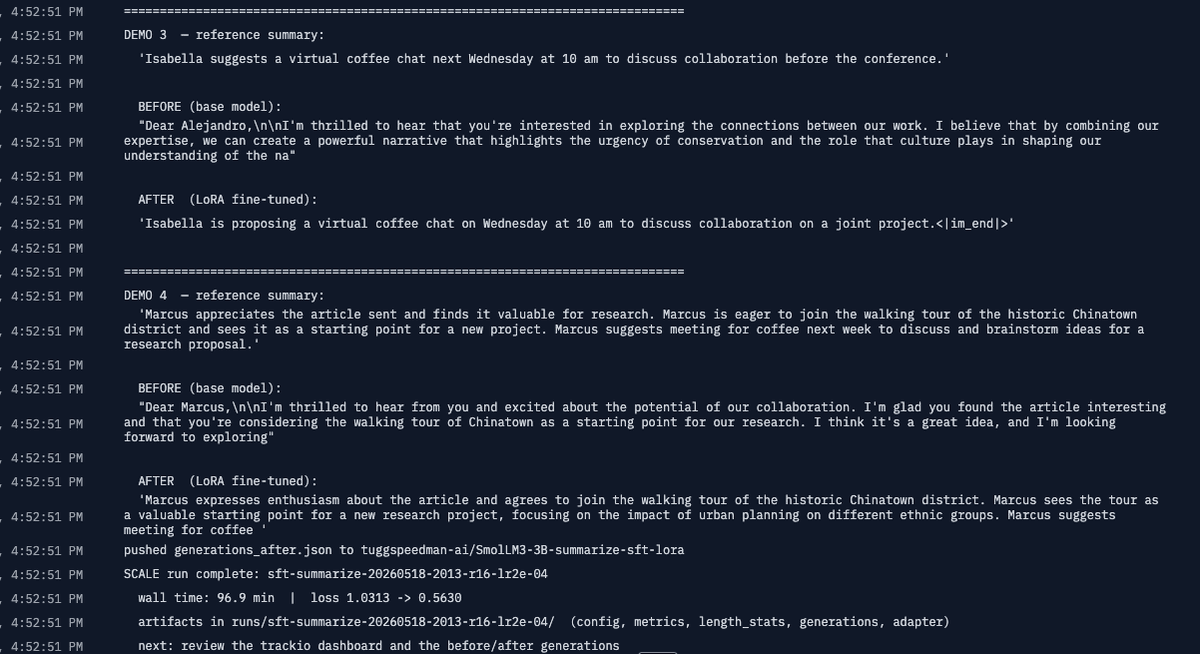
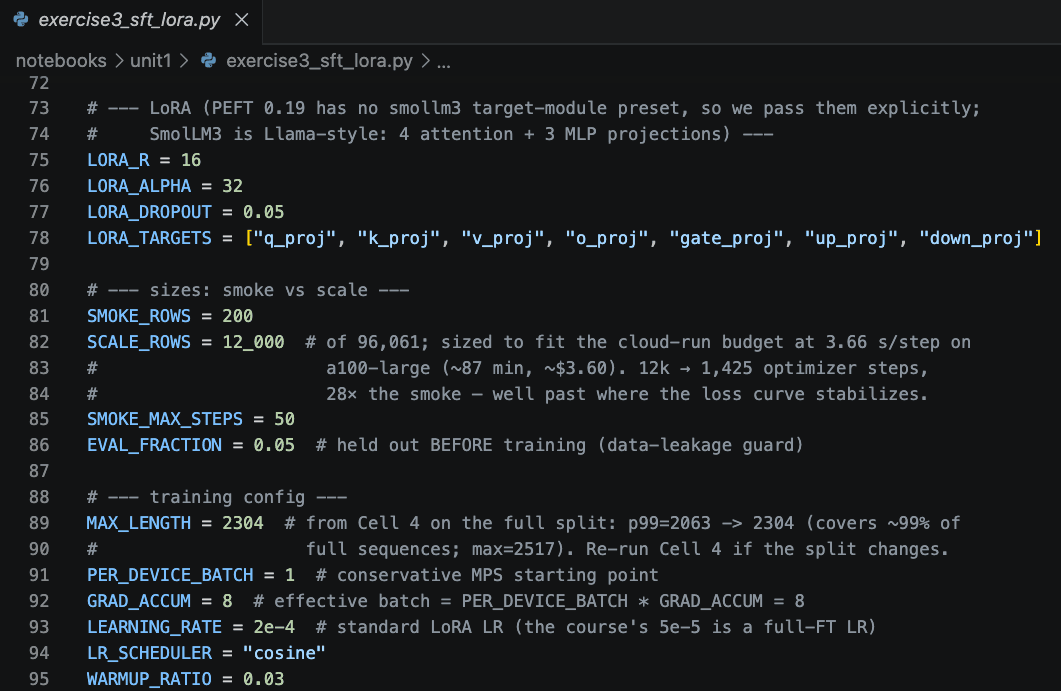
I worked through Hugging Face's Smol Fine-Tuning Language Models course and shipped a preference-aligned small model to the Hub. SmolLM3-3B-Base taken through SFT on 12k summarization examples, then DPO on 12k preference pairs, with DPO continuing to train the same LoRA rather than starting fresh (and the pre-DPO state frozen as the reference policy). A SmolVLM2-2.2B ChartQA adapter sits alongside as a vision-language sidetrack, where LoRA adapts the LLM while the SigLIP vision encoder stays frozen. Four LoRA adapters published, all reproducible from the public code.
Screenshots
Tech Stack
PyTorchHugging Face TRLPEFT (LoRA)HF Jobs (A100/A10G)Python 3.12uvTrackio