Talk2Docs
SunsetA full-stack RAG platform for chatting with PDFs, URLs, and podcasts
Overview
A RAG platform for chatting with your documents: custom chunking, hybrid retrieval, query classification, multi-document synthesis, and citation validation. Built with Next.js, Supabase, Stripe, and Clerk, deployed on Vercel and Railway.
Features
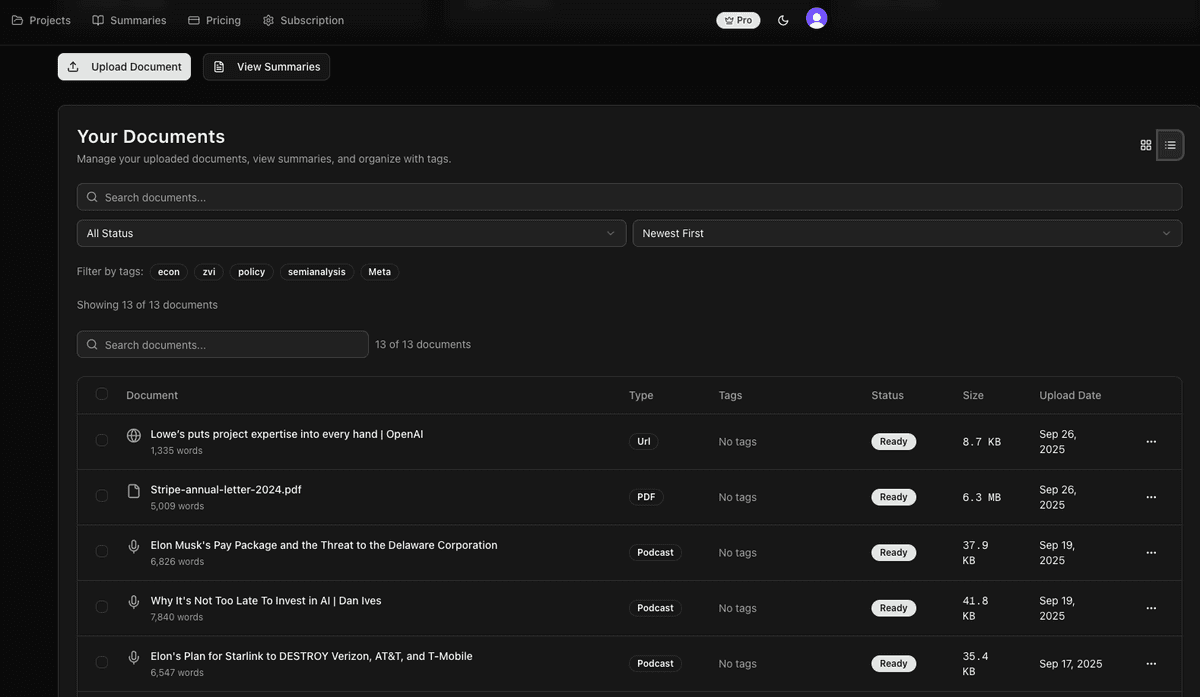
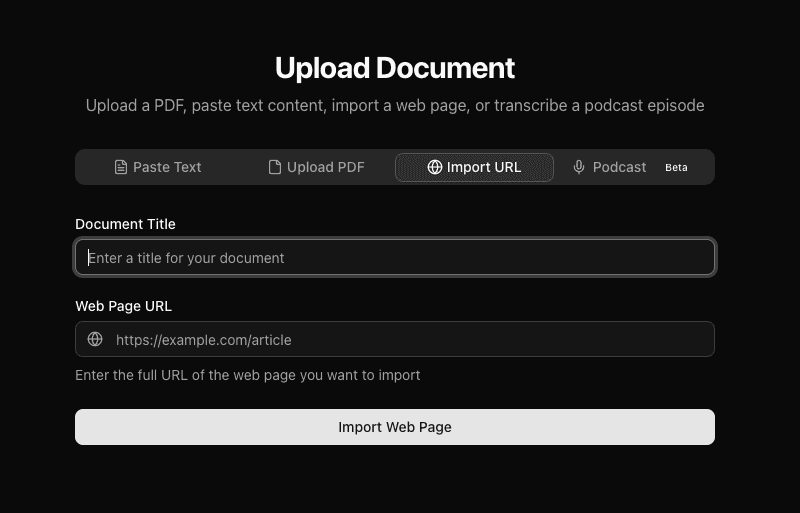
Multi-format Ingestion
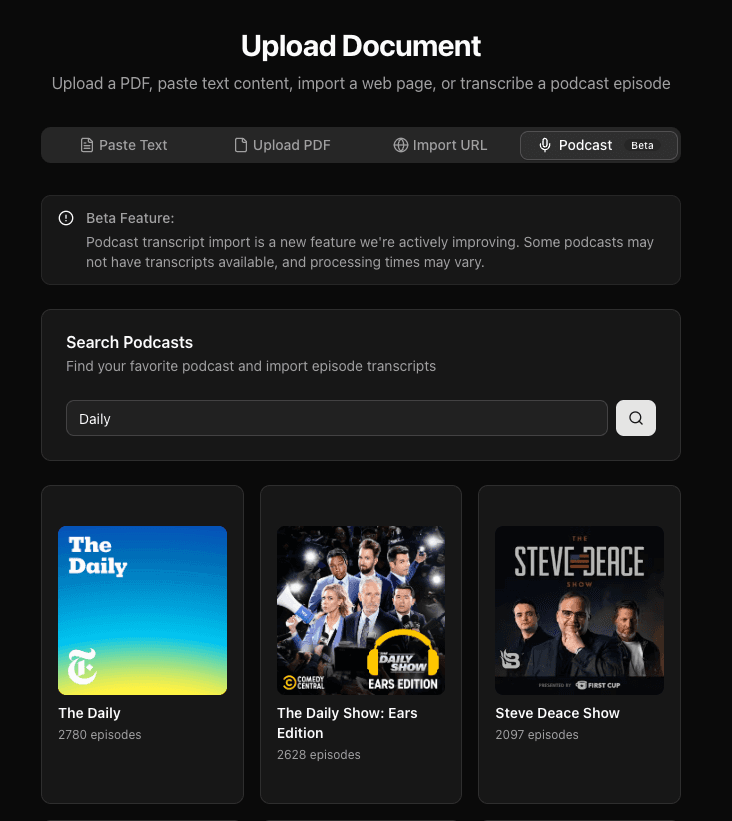
PDFs (with OCR for scanned documents), web URLs, pasted text, and podcast episodes via transcript import.
AI Chat with Citations
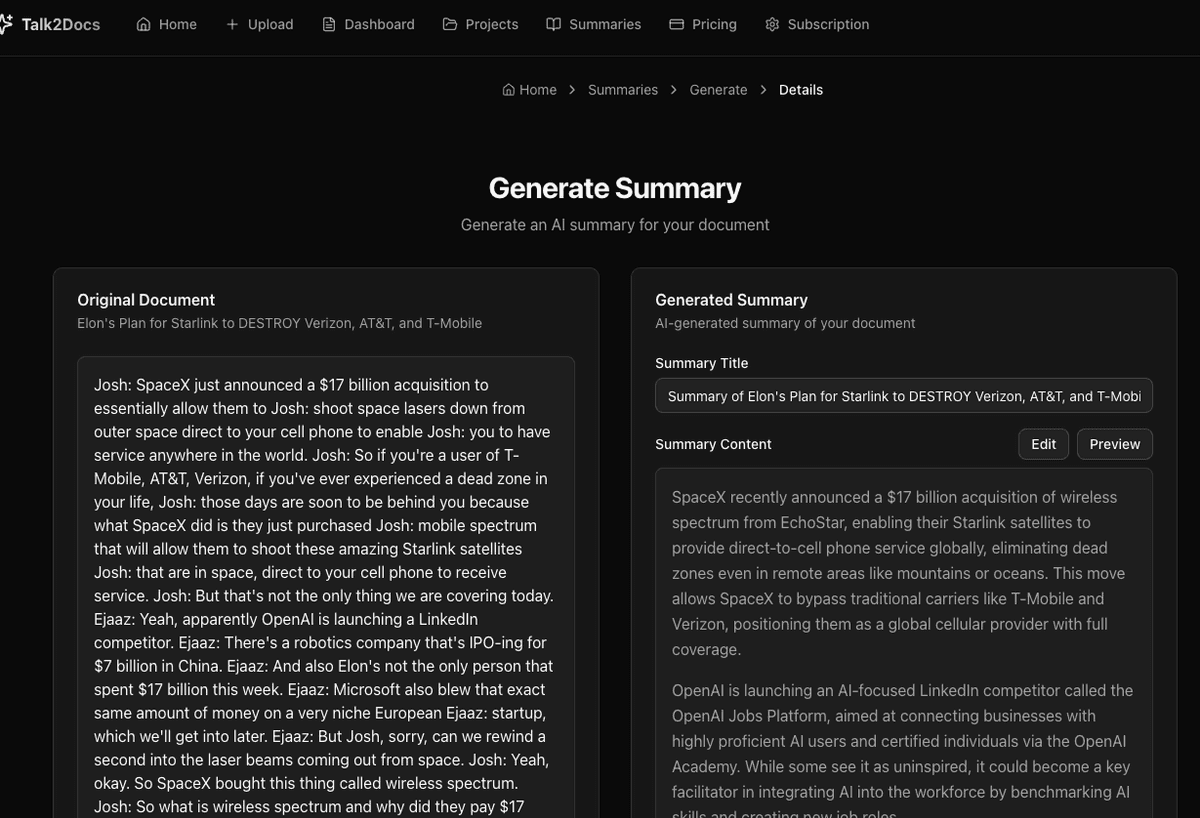
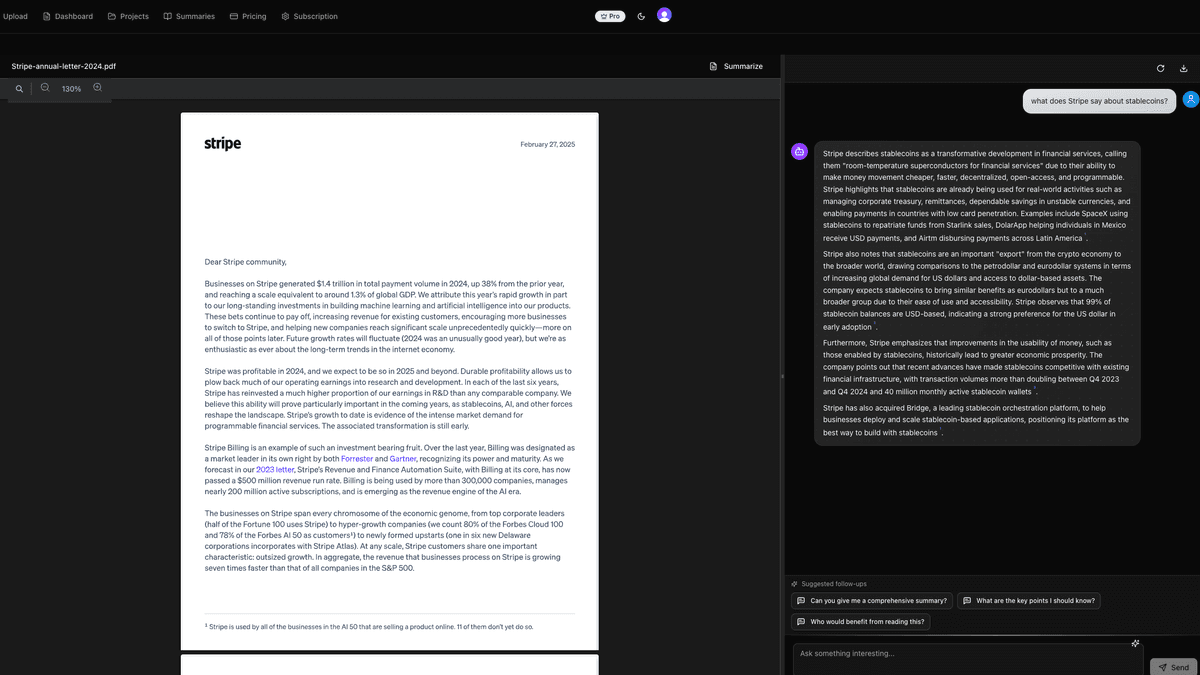
Every answer is grounded in retrieved content, with citations you can click to jump to the exact source passage.
Projects
Group multiple documents and chat across all of them. The system routes queries to the most relevant documents first.
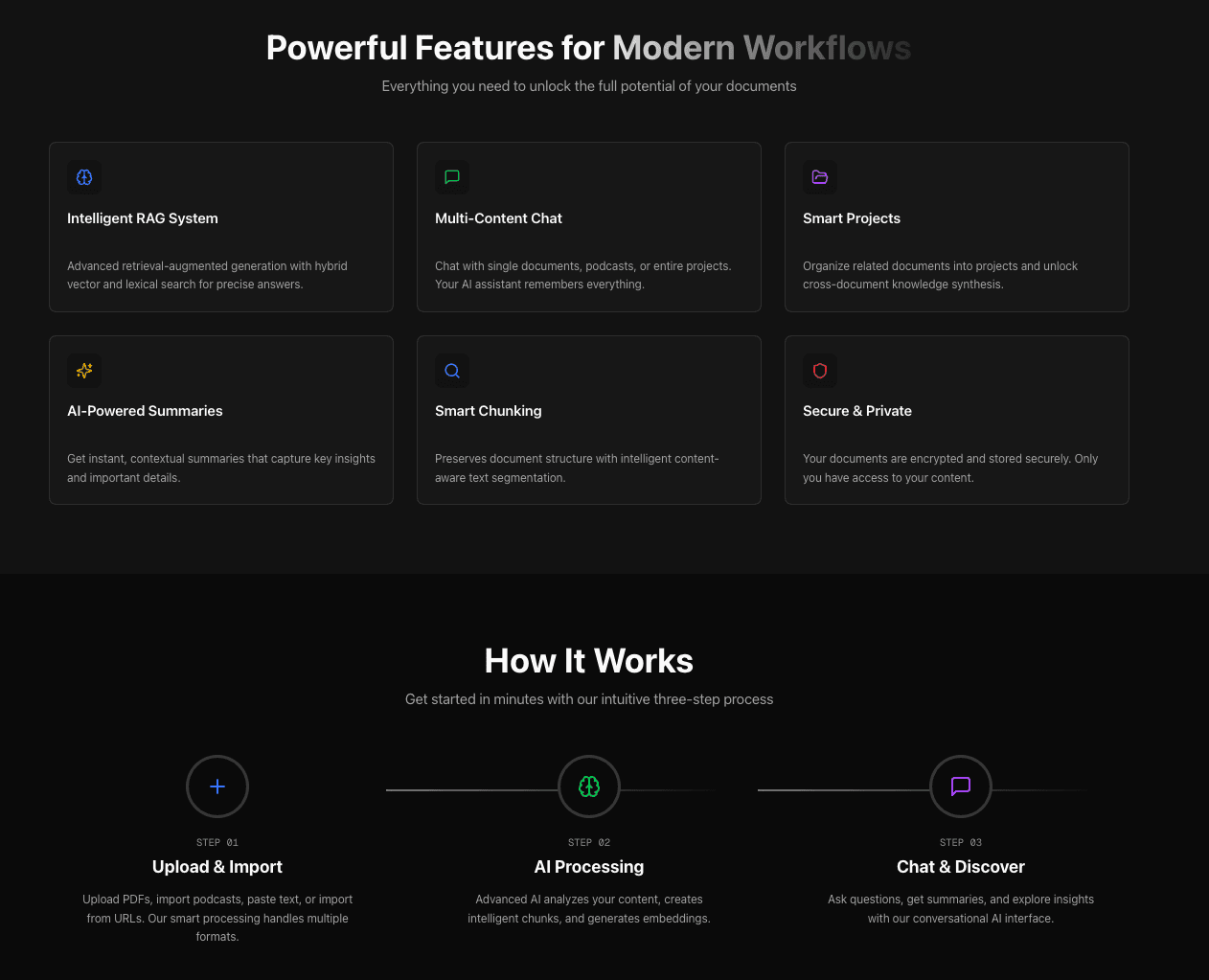
Custom RAG Pipeline
Seven-stage pipeline: query classification, rewriting, hybrid retrieval, two-tier routing, reranking, prompt composition, and citation validation.
Seven-Stage RAG Pipeline
Built every layer of the retrieval pipeline from scratch. No LangChain, no LlamaIndex. Full control over quality with independent tuning per stage.
Categorizes queries into 10 types (factual, comparison, explanation, etc.), each with a different retrieval strategy.
Three strategies (preserve, expand, aggressive-expand) based on classification. Resolves pronouns using chat history.
Vector search (OpenAI embeddings, pgvector) + lexical search (PostgreSQL full-text) with per-document-type weighting.
For multi-document queries: first score documents by metadata, select top 5, then retrieve chunks within those documents.
Cohere rerank model + Jaccard similarity filter to prevent duplicate information in context.
19-file modular library assembling prompts from 4 dimensions: base instructions, query type, document type, and chat mode.
Post-response validator checks every citation against retrieved chunks. Retries with stricter instructions if invalid.
By the Numbers
What I Learned
Built to learn
I was learning about RAG at the time, and my initial motivation was to build a retrieval system from scratch, with no LangChain and no LlamaIndex, to really understand every layer of the pipeline.
My first full product built with AI
This was the first end-to-end product I built using AI coding tools. I started with Cursor and tried different models. While building Talk2Docs, both Claude Code and Codex came out. I tried both and landed on Claude Code, which is my primary agentic coding tool today.
AI accelerates the 80%, you still own the 20%
AI tools could scaffold components and implement API routes quickly. But RAG tuning, debugging production OCR failures, and designing the two-tier retrieval system still required real problem-solving.
Shipped, learned, moved on
Talk2Docs was live for a few months with dozens of users. I learned a lot from building and operating it, then wound it down to focus on what came next.
Screenshots